Imitation learning (IL) policies in robotics deliver strong performance in controlled settings but remain brittle in real-world deployments: rare events such as hardware faults, defective parts, unexpected human actions, or any state that lies outside the training distribution can lead to failed executions. Vision-based Anomaly Detection (AD) methods emerged as an appropriate solution to detect these anomalous failure states but do not distinguish failures from benign deviations. We introduce \(\textbf{FIDeL}\) (Failure Identification in Demonstration Learning), a policy-independent failure detection module. Leveraging recent AD methods, FIDeL builds a compact representation of nominal demonstrations and aligns incoming observations via optimal transport matching to produce anomaly scores and heatmaps. Spatio-temporal thresholds are derived with an extension of conformal prediction, and a Vision Language Model (VLM) performs semantic filtering to discriminate benign anomalies from genuine failures. We also introduce \(\textbf{BotFails}\), a multimodal dataset of real-world tasks for failure detection in robotics. FIDeL consistently outperforms state-of-the-art baselines, yielding \(+5.30\%\) AUROC in anomaly detection and \(+17.38\%\) failure-detection accuracy on BotFails compared to existing methods.
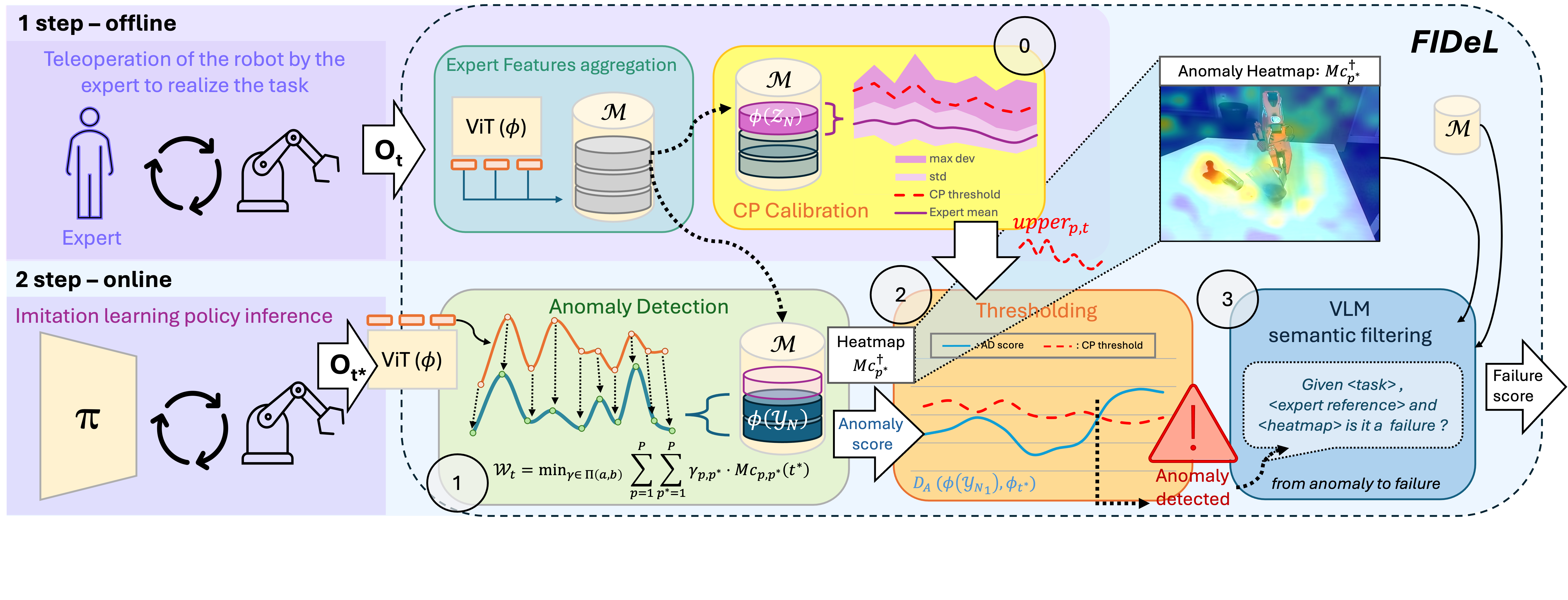
Our method comprises two main stages: an offline preparation phase and an online inference phase. During the offline phase, we process a dataset of expert demonstrations \( \mathcal{X}_N \), assumed to reflect nominal behavior, by extracting feature representations from observations. These features are stored in a memory buffer \( \mathcal{M} \), providing a compact statistical model of normal operation. In the online phase, the AD module operates concurrently with the execution of the generative policy \( f_\theta \). At each time step \( t \), the policy receives a multimodal observation \( O_t \) and outputs an action \( A_t = f_\theta(O_t) \). Prior to executing the action, \( O_t \) is encoded into the feature space, and an anomaly score is computed by comparing it to the distribution of features stored in \( \mathcal{M} \). This enables real-time monitoring of the system's behavior without interrupting the robot's control loop. By decoupling the modeling of nominal behavior from online evaluation, the proposed two-stage architecture ensures computational efficiency which enhance reliability by promptly detecting deviations from expected operational patterns.
To rigorously evaluate the effectiveness of our AD approach, we introduce \( \textbf{BotFails} \), a dedicated dataset specifically designed for robotic AD tasks. Our method is benchmarked on this dataset alongside several state-of-the-art baseline methods adapted to our experimental setting. The BotFails dataset comprises a diverse set of tasks, each designed to represent a specific human activity or interaction scenario within a controlled environment. In total, the dataset contains 414,359 annotated frames across 646 video sequences, offering a rich and varied benchmark for evaluating anomaly detection systems. Each task in the dataset is associated with a predefined set of anomalous behaviors. These anomalies are deliberately introduced to mimic realistic deviations from normal patterns, such as incorrect object handling, wrong execution of the expected task, or unexpected presence of foreign objects.

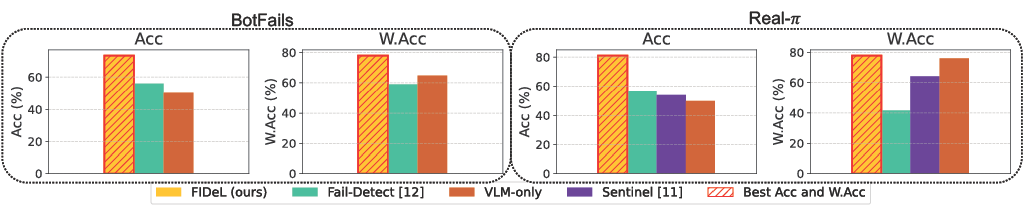
We evaluated FIDeL along with several SotA baselines on BotFails. FIDeL delivers the highest overall performance, achieving an average Weighted Accuracy of \( \textbf{78.65%} \) on BotFails and \( \textbf{77.71%} \) on Real-\(\pi\), exceeding the best-performing baseline, \( \textit{logpZ0} \), by more than 20 points in Weighted Accuracy. AD modules suffer a sharp performance drop when benign anomalies are relabeled as nominal, especially in TNR; Adding semantic filtering significantly mitigates the TNR degradation, enabling more balanced detection (\( \textbf{85.8%}\) TPR / \( \textbf{74.8%}\) TNR). Fail-Detect tends to overpredict anomalies, as it cannot distinguish true failures from benign deviations, while Sentinel favors nominal predictions, likely missing failures that are purely visual and not reflected in proprioceptive signals. These results show that semantic filtering is crucial for reliable failure monitoring—avoiding unnecessary interventions while still capturing genuine failures.

@inproceedings{rolland2026failure,
title={Failure Identification in Imitation Learning via Statistical and Semantic Filtering},
author={Rolland, Quentin and Mayran de Chamisso, Fabrice and Mouret, Jean-Baptiste},
booktitle={IEEE International Conference on Robotics and Automation (ICRA)},
year={2026},
}


